


Why AI Red Teaming Must Evolve Beyond the Static Probing Era
Every week, another company announces a new AI assistant, agentic workflow, or retrieval-augmented application. And every week, the security posture protecting those deployments lags further behind. The gap is not primarily a tooling gap. It is a conceptual gap the industry is applying legacy security paradigms to a fundamentally different class of system, and paying the predictable price.
Most AI red teaming tools available today are, to put it plainly, static scanners with a modern rebrand. They replay pre-compiled lists of well known jailbreak prompts against an endpoint and report whether the AI outputs something offensive. This is not red teaming. It is a vocabulary quiz for a system that has already moved past vocabulary. Well-known jailbreak products are increasingly incorporated into detection signatures, reducing their offensive value even further.
This article makes a case that I think is overdue in our industry for context-aware, kill-chain-aware AI red teaming is not a premium add-on for well-resourced enterprises. It is the minimum viable security posture for any organization deploying AI with real-world tool access. I’ll explain why the problem is structural, what the empirical evidence tells us, and what a credible solution architecture actually requires.
1. The “Built-In” Illusion
The Shared Responsibility Gap
The dominant AI security assumption in most enterprises is a direct import from cloud computing where the provider secures the model; we secure our business logic. In cloud infrastructure, this boundary is relatively clean. In AI application deployment, it is not.
A foundational model provider, OpenAI, Anthropic, Google, xAI, is responsible for the model layer, the training pipeline, the base safety alignment, and the API infrastructure. They are not responsible for how their model is integrated with your payroll database, your customer ticketing system, or your internal code execution environment. That surface, the application layer, belongs entirely to the deployer. The gap between these two layers is precisely where enterprise AI security breaks down.
CISA’s guidance on AI system evaluation makes this explicit statement that application-layer risks arising from tool integrations, retrieval pipelines, and memory systems are the deployer’s domain. Organizations operating under the built-in illusion are not just poorly defended; they are working from a factually incorrect model of their own attack surface.
The Courts Are Paying Attention
The legal system is building a liability framework that is going to force this reckoning into boardrooms. The Mobley v. Workday case, in which a federal judge rejected Workday’s motion to dismiss discrimination claims arising from its algorithmic hiring system, established a principle that security practitioners need to internalize, which is companies that deploy AI decision-making systems can be held directly liable for the outcomes those systems produce. The court’s reasoning treated Workday as an agent of the employers who relied on it, bearing accountability commensurate with that reliance.
The trend is accelerating. Subsequent class action suits targeting AI-driven hiring platforms have reinforced the doctrine that if you offer an AI application as a service and act as the intermediary between a powerful model and a consequential decision, you own the security and accuracy liability that attaches to it. Relying on an API provider’s default guardrails is no longer a business decision. It is a board-level legal risk.
2. First Principles - Why Static Red Teaming Is Scientifically Invalid
The “Data Is Code” Architectural Reality
To understand why scanning tools fail against LLM applications, you have to start at the architecture level. In classical computing, there is a strict, enforceable separation between executable code and user data. SQL injection works precisely because it violates that boundary. The fix, parameterized queries, enforces it at the parsing level.
In an LLM, that boundary does not exist by design. Natural language is simultaneously the instruction set and the data substrate. A developer’s system prompt, a retrieved document from a corporate wiki, a user’s input, and a malicious payload embedded in an uploaded PDF are all processed through the same token-prediction mechanism.
The UK National Cyber Security Centre articulated this clearly, prompt injection is not simply a variant of SQL injection. It is structurally different because there is no reliable parser-level boundary to enforce. The mitigation playbook that defeated SQL injection does not translate. Their conclusion, that prompt injection should be treated as a residual, architectural risk requiring containment-first design rather than prevention-first patching, is the correct mental model for any red team evaluating LLM applications.
Non-Determinism Makes Point-in-Time Testing Invalid
Traditional software is deterministic. A given input produces a given output, consistently, across time. This makes point-in-time penetration testing a binary case, a vulnerability either exists in the code or it doesn’t.
LLMs are probabilistic. Their outputs are sampled from a probability distribution over possible next tokens. The same input can produce materially different outputs across sessions, temperature settings, and model versions. More critically, model providers continuously update weights in the background, often without version-specific notice to API consumers.
An empirical study from Stanford and UC Berkeley quantified this risk in striking terms. Researchers tracking GPT-4’s behavior over several months found that the model’s accuracy on prime number identification dropped from 84% to 51% between March and June 2023 with no corresponding API update announcement.
The security implication of an application that safely blocks a malicious prompt on Monday may blindly execute the identical prompt on Friday because the provider silently updated model weights. A penetration test conducted in Q1 may be operationally meaningless by Q2. Relying on a fixed corpus of known jailbreaks to evaluate a probabilistic, continuously evolving system is like trying to measure a cloud with a ruler.
3. The Promptware Kill Chain - How Attacks Actually Work
From Toxic Text to Weaponized Agency
The first generation of generative AI risk concerns centered on content safety around whether an AI say something harmful? These remain valid concerns. But for enterprise security practitioners, they have been substantially superseded by a more operationally critical threat class.
Modern enterprise AI is not a chatbot in a browser tab. It is an agent integrated with live databases, internal APIs, email systems, code execution environments, and financial transaction platforms. The blast radius of a compromised agent is not a bad tweet. It is unauthorized database access, exfiltrated PII, manipulated financial records, or a persistent backdoor in an internal codebase.
The OWASP Top 10 for Large Language Model Applications identifies Excessive Agency as a top-tier critical vulnerability precisely because of this shift. The threat is no longer about tricking an AI into generating harmful text. It is about manipulating an AI into invoking its granted tools, calling APIs, executing shell commands, writing to databases, in ways that violate intended policy. An AI granted the permissions it needs to do its legitimate job is, from an attacker’s perspective, a pre-authenticated insider threat waiting to be activated.
A Formal Framework for Multi-Stage AI Attacks
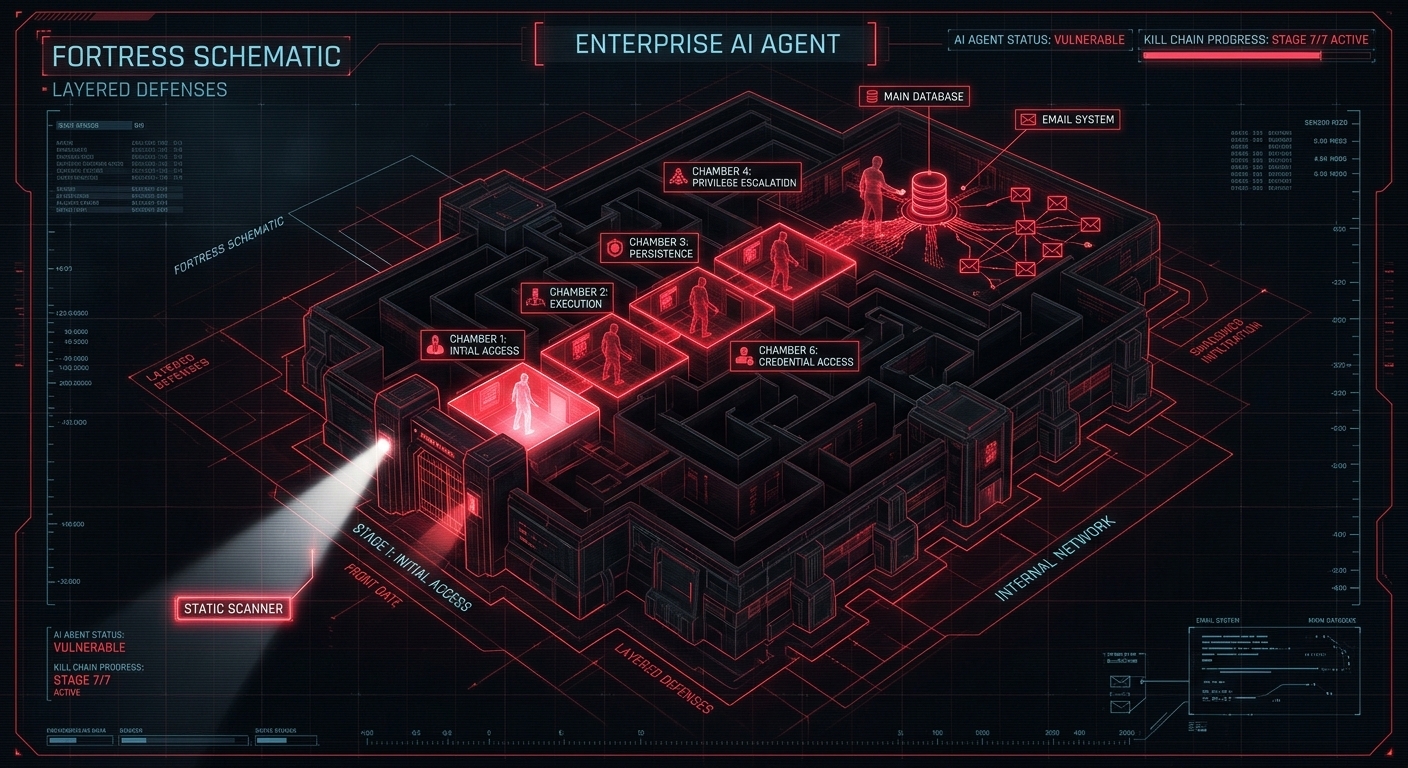
The most important conceptual advance in AI threat modeling in recent years is the formalization of multi-stage AI attacks as a structured campaign. Published in January 2026, the Promptware Kill Chain by Ben Nassi, Bruce Schneier, Oleg Brodt, and Elad Feldman provides the first rigorous taxonomy of how adversaries move from initial access to full objective realization within an agentic AI environment. The authors analyzed 36 documented incidents and real-world studies and demonstrated that at least 21 attacks traverse four or more stages of the chain. This is not a theoretical model. It is a documented pattern.

Seven stages of the Promptware kill chain are:
Stage 1 - Initial Access - Direct or indirect prompt injection through user input, uploaded files, retrieved web pages, or poisoned documents in the AI’s retrieval corpus.
Stage 2 - Privilege Escalation - Jailbreaking to override system prompt guardrails, either through direct instruction or multi-turn conversational manipulation.
Stage 3 - Reconnaissance - Systematic probing to map the AI’s tool inventory, API permissions, data access scopes, and decision-making policies.
Stage 4 - Persistence - Poisoning memory systems or RAG vector databases with malicious instructions that survive beyond the current session.
Stage 5 - Command & Control - Establishing a retrieval-based C2 channel by having the AI periodically fetch adversary-controlled content to receive new instructions asynchronously.
Stage 6 - Lateral Movement - Exploiting the AI’s integrations to spread the attack, using a compromised email-connected agent to propagate payloads, or probing adjacent systems via internal tool access.
Stage 7 - Actions on Objective - The main goal could be data exfiltration, unauthorized financial transactions, credential harvesting, or insertion of persistent malware into connected codebases.
Here is the critical operational point, virtually every AI red teaming tool on the market today tests primarily Stages 1 and 2, prompt injection and basic jailbreaking. They probe the chat input interface and report whether the AI produces unsafe text. Stages 3 through 7 are almost entirely unaddressed. An organization could pass every test in a static scanner’s library and remain fully exposed to an adversary who understands their application’s tool graph.
4. The Economic Asymmetry - You’re Bringing a Checklist to a Machine Fight
There is a third dimension to this crisis that doesn’t get enough attention, which is the economics have completely broken against the defender.
Threat actors are no longer writing manual jailbreaks. They are using automated adversarial LLMs to generate, test, and refine attacks at machine speed. Academic research has proven the scale of this threat. The Tree of Attacks with Pruning (TAP) framework demonstrated that an attacker LLM operating without human intervention can achieve attack success rates exceeding 80% against frontier models. The PAIR algorithm achieves comparable results in as few as 20 queries by using iterative attacker-LLM feedback loops to refine jailbreaks in real time.
The most recent evidence of this arms race came in February 2026, when the UK AI Security Institute published Boundary Point Jailbreaking (BPJ), a fully automated, black-box attack algorithm that required no human-crafted seed prompts. AISI demonstrated BPJ against two of the major AI labs deployed defense systems which are Anthropic's Constitutional Classifiers, which had previously withstood over 3,700 hours of human red-teaming with only one successful breach, and OpenAI's input classifier for GPT-5. BPJ broke both. BPJ broke Anthropic's Constitutional Classifiers at a cost of approximately $330 and OpenAI's GPT-5 input classifier for approximately $210." The AISI team's own defensive conclusion is telling that single-interaction defenses that evaluate one request at a time are insufficient against this class of attack. They recommend batch-level traffic monitoring that detects suspicious patterns across sessions, a layered, systemic defense, not a classifier patch.
These systems generate thousands of iteratively refined adversarial variants. The same malicious intent expressed in different framings, personas, and surface forms, rendering any static, signature-based detection approach useless.
Both NIST AI 600-1 and the AI Risk Management Framework frame AI risk management as a continuous lifecycle discipline, not a point-in-time certification exercise. The economic asymmetry of adversarial AI transforms this from a best-practice recommendation into an operational necessity.
5. What Adequate AI Red Teaming Actually Requires
Solving the compound failures of static red teaming, context blindness, single-stage scope, point-in-time invalidity, and economic disadvantage, requires a fundamentally different approach. CISA’s TEVV (Testing, Evaluation, Validation, and Verification) framework for AI provides a useful baseline for what the next generation of tooling must deliver.
There are four requirements:
- Context ingestion before any test runs. A tool that doesn't know your application's tool inventory, data access scopes, memory configuration, and orchestration policies before running a single test is not testing your application. It is testing a generic chatbot that happens to share an API endpoint with your application.
- Adaptive, kill-chain-conditioned test planning. Attack sequences must be derived from the specific application's permission model and data flows, and must cover all seven stages of the Promptware Kill Chain. An engagement that never attempts RAG poisoning, tool abuse, or lateral movement against your actual integrations has not tested your application's real threat surface.
- Continuous threat telemetry, not snapshots. Binary pass/fail scores are inadequate for non-deterministic systems. Adequate tooling must measure how quickly safety guardrails degrade under sustained adversarial pressure and how close outputs have come to actionable exploitation across a multi-turn session.
- Assurance artifacts, not reports. Findings must be reproducible, severity-rated by business impact rather than prompt severity alone, and mapped to recognized AI security taxonomies. OWASP LLM Top 10 covers vulnerability classification; MITRE ATLAS, the AI-specific extension of ATT&CK, covers adversary technique mapping. A document you can't re-run after remediation is a liability record, not evidence of risk management.
Most of the AI security products I’ve evaluated, across both dedicated red teaming tools and broader AI platforms, fail at requirement one. They are model-centric by design. They test whether a model will say something it shouldn’t. They do not model the application, its permissions, or its kill chain exposure.
There are credible tools working in this space. Garak (open source, from NVIDIA) and Microsoft PyRIT are serious, extensible frameworks, but they require significant engineering investment to configure meaningfully for a specific application. The common gap across all of them remains the same. Which is that none are primarily architected around the Promptware Kill Chain as an evaluation model. The industry still has no purpose-built adversarial LLM that ingests your application context, builds a bespoke threat model, and adaptively navigates the full seven-stage chain.
That's the gap I'm building toward. I'm currently developing and testing a context-aware red teaming LLM designed specifically for agentic applications, one that operates as an adaptive adversary rather than a static scanner, and produces the evidence-grade artifacts that enterprise security programs actually need. I have been competing in AI red teaming competitions specifically to build ground-truth data on how agentic systems fail across these stages. I'll share more on the architecture as it matures.
6. Where This Leaves Enterprise Security Teams
The era of trusting default AI guardrails and running static vulnerability scans is over. The argument is not rhetorical. It is mathematical, architectural, and empirical.
Probabilistic model drift means any AI security assessment carries an expiry date measured in weeks. The boundary between executable instruction and untrusted data, enforced in traditional systems through hardware and OS-level controls, does not exist in LLMs, making prompt injection a permanent residual risk that demands containment-first architecture rather than prevention-first patching. Agentic AI has handed threat actors pre-authenticated insider access to enterprise infrastructure, and the Promptware Kill Chain gives them a structured playbook for exploiting it. Automated adversarial LLMs give them the economic scale to do so at machine speed.
Against this backdrop, static scanners and checkbox compliance against fixed prompt libraries are not merely insufficient. They represent a categorical mismatch between the nature of the threat and the nature of the defense.
For security teams navigating this now, the practical priorities are to audit your AI applications’ tool permissions and minimize them aggressively (OWASP’s Least Privilege guidance on Excessive Agency is the right starting point); treat RAG pipeline inputs as untrusted and implement sanitization controls; and design your security architecture on the assumption that initial access will occur, then focus your controls on breaking subsequent kill chain links before they reach impact.
The Promptware Kill Chain gives our industry a shared, empirically grounded framework for understanding the AI attack surface. The work of building security programs adequate to that framework, ones that produce verifiable evidence, evolve continuously, and treat agentic AI as the genuinely novel threat surface it is, is no longer theoretical. It is urgent.
Part of the “Smashing the AI Stack” research series




